
The Bellrock Project

“Bell Rock Lighthouse” by Derek Robertson. Licensed under CC BY-SA 2.0
Abstract
There are millions of smartphones people carry around that support Bluetooth Low Energy. All these phones could be used as Bluetooth beacons, i.e. to periodically emit a signal carrying certain information such as ID, location or name of a place. These signals could be used by other phones to infer location, an event one is attending or proximity of friends. The goal of this project is to develop infrastructure which would support that while protecting a user’s privacy by changing the emitted ID each time a device changes its place. A server will be used to maintain the anonymity of the clients while giving them benefits as if static client UUIDs were used.
Why Bellrock?
The Bell Rock Lighthouse, off the coast of Scotland, is the world’s oldest surviving sea-washed lighthouse. It was built between 1807 and 1810 by Robert Stevenson.
Progress
2016-06-02: The last couple of weeks were spent by polishing the dissertation and adding bits of evaluation code. The dissertation is now handed in (1 day before the deadline!). The final line count is 9,337 and the figure below shows how Bellrock progressed in terms of lines of code as the time went. It was a very enjoyable project and the final pdf can be find in the Publications section. [9,337 LOC]
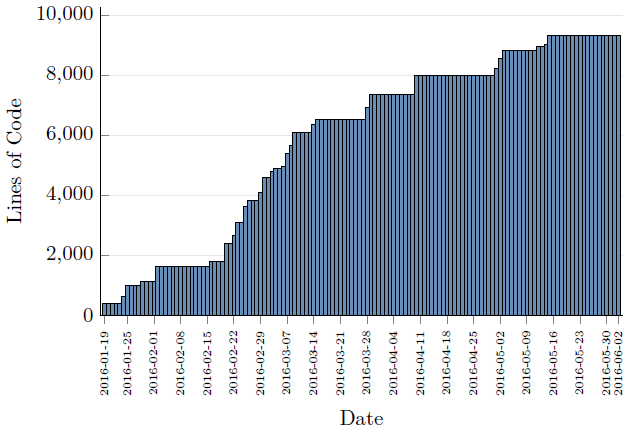
The number of lines of code of Bellrock as time went
2016-05-18: First draft of the dissertation is ready. [9,323 LOC]
2016-05-16: Server performance evaluation section done. This was a rather intense section in the dissertation and it involved running and benchmarking the Bellrock server a lot. I finally managed to get the figure I was very curious about: comparison of the server performance with and without the heuristics. [9,323 LOC]
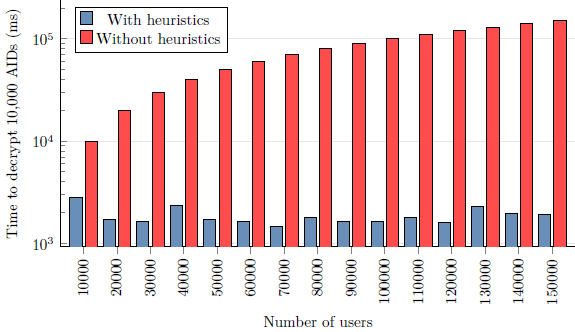
Comparison of server decryption speeds with and without heuristics. The number of users per cell tower is set to 1,000. Note that the y-axis has logarithmic scale.
2016-05-15: Code for benchmarking the raw AID decryption performance. This also generates graphs which show how the time depends on the number of users and the number of observations. [9,323 LOC]
2016-05-14: More work on the Evaluation chapter. The Bat System statistics section is now done. New figure with user count for each day is now generated. Also, some small fixes were added and the figures are now consistent. [9,024 LOC]
2016-05-13: Work on the Evaluation chapter. This involved looking into the evaluation code as well and couple of bugs were fixed and smoothing was added into the movement computation so that small time differences in the logs don’t cause false movement. [8,980 LOC]
2016-05-12: Plenty of work on the dissertation, first draft almost ready. Moreover, refactoring bits of code: Since there are three logs (Lab, AT&T and testing), I used to hold couple of constants for each. Changing the log which is being used was pain, as lot of lines in the code had to be changed. Now the log constants are together in a LogSettings object which encapsulates them all. Switching logs is now faster and safer. [8,958 LOC]
2016-05-03: Finally, the logs have no non-chronological singularities. As a part of this work, I moved from a awk script that merged the raw Bat Logs with file-relative timestamps into one single log with absolute timestamps to a Java approach. Faster, cleaner and includes chronology checker. I also reworked the Bat Log to meetings log convertor. This lead to 6-fold reduction in RAM consumption and about 20-fold speed-up. Moreover, the evaluation architecture is complete for the moment being. The work now shifts to the dissertation. A sample figure generated today is below. [8,818 LOC]
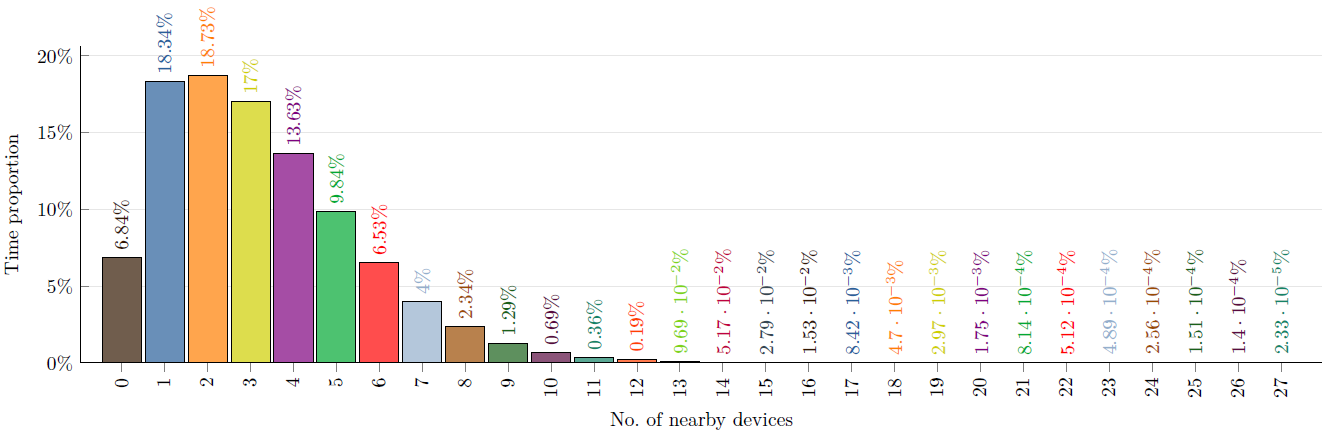
The proportion of time any device was within 7.5 m range of a certain number of static (and hence beaconing) devices
2016-05-02: Lot of further work on the logs. I found some duplicates in the logs causing them making then not chronological. This caused some problems in the statistics I extracted from the logs. This is now fixed and automatically checked for. Moreover, I refactored parts of the code, making them easier to extend. Thanks to this I now export three more LaTeX figures with statistics. [8,564 LOC]
2016-05-01: My exams are over, work on the project resumes. I am now able to export my evaluation histograms into LaTeX. Hence evaluating the system can now be done on much faster pace. A testing screenshot of the histogram included. [8,236 LOC]
2016-04-10: Studying for the exams, so I almost no time doing the project at the moment. However, I changed the way the statistics are computed for nearby devices. Only those intervals where there was at least one active device in the system are now considered. Therefore, the histograms now make more sense and they are not skewed by nights, weekends and holidays. This involved extracting new log with active users and also creating new general-purpose log reading and parsing infrastructure, which is rather elegant and it will lead to deleting a lot of duplicated code. [8,015 LOC]
2016-03-29: Further work on obtaining statistics from the logs. I got the AT&T logs now which contain more data. This revealed some memory problems and I had to rewrite bits of the log parser, etc. Instead of loading the entire log in the first step, the logs are now processed in batches (or lazily loaded) and written immediately as results are available. This lead to huge speed-up and also significantly lower memory requirements. I used a lot of Java 8 features, such as NIO and streams to make the code shorter. I also discovered Guava’s PeekingIterator, which offers “non-destructive” peek() on the next element. [7,374 LOC]
2016-03-28: Extracting more data from the Bat Logs to get good estimates on typical user behaviour and on the requirements that the use-cases impose on the Bellrock server. When using the Bat Logs to properly simulate the Bellrock client behaviour, I found out that in the Bat Log environment about 1,300 AIDs are observed per user per day on maximum. I will therefore further assume that scaling the server to be capable of resolving 5,000 AIDs per user per day is reasonable for all practical purposes. Moreover, further work on the paper. [6,926 LOC]
2016-03-16: Work on the paper. [6,532 LOC]
2016-03-15: I upgraded the decryption heuristic to minimise the database accesses which were the performance bottleneck. Now the system is perfectly scalable. For instance, in a theoretical country with 100,000 people, 764 cell towers, one observer at each cell tower making 1,000 observations, the decryption of all the 764,000 observations takes about 74 seconds.
The naive system would need to perform on average (100,000 / 2) × 1,000 × 764 = 38,200,000,000 decryptions. That would take it 38,200,000,000 / 5,680,000 = 6,725 seconds. The system incorporating the heuristic is therefore about 100 times as fast!
The most important thing is that the complexity of the naive system is $ O(u \cdot o \cdot r) $ where $ u $ is the number of users in the system, $ o $ is the number of observers and $ r $ is the number of observations. The complexity of the system incorporating the heuristic is $ O(o \cdot r \cdot c) = O(o \cdot r) $ where $ c $ is the average number of users per cell tower which is bounded by a constant. [6,532 LOC]
2016-03-14: The decryption with heuristics now works! Also, I reimplemented the last recently seen user cache using LinkedHashSet, it is now significantly faster than the previous implementation. However, the heuristic decryption overall achieves at the moment only about 800,000 AID decryptions per second due to a lot of slow database accesses. [6,360 LOC]
2016-03-13: Started work on the Bellrock paper. [6,100 LOC]
2016-03-09: I switched to a 64-bit JVM. Thanks to this I can allocate more than 1.5 GB of memory to the server. Running the server with 2 GB of memory lead to significantly improved Anonymous ID decryption speeds, achieving decryption speed of 5,680,000 AIDs per second. So with 100,000 users on the server, the average time to correctly decrypt an Anonymous ID would be 8,8 ms.
The heuristic Anonymous ID decryption is now implemented. Testing it with as realistic data as possible: Czech Republic has about 10 million people, 72,000 km2 and about 100,000 cell towers. For comparison, United Kingdom has about 65,000,000 people, 240,000 km2 and about 300,000 cell towers. So the number of cell towers is proportional to the area rather than population.
Work on the main simulation that simulates the heuristic Anonymous ID decryption started. [6,100 LOC]
2016-03-08: Implemented the OpenCellID cell tower information to coordinates conversion. In order to map people using different cell towers at the same location to the same position, I have to round the obtained GPS coordinates of the cell tower. The rounding will be to 2 decimal points, which gives resolution of 1.1 km at the equator and about 800 meters in London. However, the online API is too slow for the project’s purposes (it takes about 120 ms to resolve the location of one cell tower). To address this, I downloaded and pre-processed a OpenCellID database into a hash map (cell tower ID to location) that has much faster (< 0.5 ms) access times. [5,669 LOC]
2016-03-07: Work done on decryption heuristics. This involved adding new database table storing the locations of users during time. Moreover, I started implementing the Cell ID to coarse location infrastructure. Fortunately, the cell ID and all the other information can be efficiently packed into a single long (hence enabling efficient storage):
// Take last 28 bits this.cellID = (int) (cellTowerInfoPacked & 0x0000_0000_0FFF_FFFFL); // Next 16 bits this.lac = (int) ((cellTowerInfoPacked & 0x0000_0FFF_F000_0000L) >>> 28); // Next 10 bits this.mnc = (short) ((cellTowerInfoPacked & 0x003F_F000_0000_0000L) >>> 44); // Next 10 bits this.mcc = (short) ((cellTowerInfoPacked & 0xFFC0_0000_0000_0000L) >>> 54);
Also, the database can now be efficiently queried for all users that were at the wrong time at the wrong place :-), i.e. those who could have sent the Anonymous ID certain user heard. [5,392 LOC]
2016-03-06: Hopefully final design of protocols enabling location-based heuristics when decrypting the UIDs:
- Client A broadcasts its Anonymous ID. Include also the Mobile Country Code (10 bits) to decrease the number of clients to test in case full brute-force decryption.
- Client B hears the message containing the Anonymous ID of client A and records it in the Observation object. Client B also records its current approximate position in the Observation object. The approximate position is determined using OpenCellID, i.e. the cell tower ID is transformed into the cell tower WGS84 coordinates which are then rounded, so that all clients around that tower share this approximate coordinate.
- Client B connects to the server and sends its Observation list and a list of its positions during the day.
Server does the following for each Observation:
- Tries to decrypt the Anonymous ID in the Observation using keys of B’s k (~ 1,000) most recently met clients. [~ 1,000 decryptions]
- Unless 1. succeeded, tries to decrypt the Anonymous ID in the Observation using keys of B’s peers. [~ 500 decryptions]
- Unless 2. succeeded, tries to decrypt the Anonymous ID in the Observation using the keys of clients, who were at the same approximate position at the same time. [~ 10,000 decryptions]
Now the server should have resolved the Anonymous ID with high probability using on average less than 11,000 decryptions (rather than n decryptions, where n >> 11,000 is the total number of clients in the system). This should take on average less than 1 ms per Observation, which is reasonable.
The third step in the decryption will succeed only if client A connected to the server before this decryption and told the server about its positions during the day. If not, the Anonymous ID won’t be decrypted. In this case, we can do two things: Re-try the decryption later or leave the Anonymous ID unencrypted, since there will be plenty of other data that will provide the server with the necessary information. [4,965 LOC]
2016-03-05: After further enhancements (using parallel stream and increasing the maximum heap memory) I managed to get the Anonymous ID decryption performance to 3,925,000 AIDs per second. So with 100,000 users on the server, the average time to correctly decrypt an Anonymous ID would be 12,7 ms. [4,908 LOC]
2016-03-04: Huge performance win on the method that decrypts the Anonymous IDs by keeping initialised Cipher objects for each user. Now Anonymous ID can be encrypted in about 1 microsecond with 100,000 users in the system! I also tested using OpenSSL implementation, but the cross-language communication caused huge overhead. I also refactored some code and made it more elegant. Further optimisation possibilities lie in parallelisation of the decryption. [4,908 LOC]
2016-03-03: A lot of work on the server performance. Bulk user creation sped-up 100 times, i.e. the server can now create 100,000 users in 2,360 milliseconds. Speed-up due to sending commands to the database in bulk. This also made Observation adding 100 times faster.
I also made the Anonymous ID decryption 2 times faster by reusing the Cipher object. This is fully secure, as Cipher.init() wipes the previous state. Further thinking on how to speed this up even further: Using C/C++ implementation or storing the initialised Cipher objects. [4,808 LOC]
2016-03-02: Meeting with supervisor. Talked about the problem I spotted yesterday. It is not such a big issue, since lot of clients will be in the system, hence not being able to resolve all of them is not such a big deal. And once they connect, their cell tower ID history will be known and stuff can be therefore efficiently decrypted afterwards. [4,605 LOC]
2016-03-01: The key store is now an encrypted HSQLDB, since the Key Store done using Java performed very poorly. Server can create 10,000 new users and generate keys for each of them in 20 seconds. Decryption performance to be tested.
I spotted a problem in the planned location-assisted decryption. There is no way for the server to learn where the offline clients are. Therefore, the system will most likely have to rely only on friends, recently met, others decryption heuristics. [4,605 LOC]
2016-02-29: The server database and user infrastructure is done. The server is now capable of storing users, their keys, list of peers of users and observations of Anonymous IDs of every user. [4,098 LOC]
2016-02-26: The server database (HSQLDB) is now working and running and protected by a big unit test. The system has 4 tables (UIDS, Keys, Peers and Observations). Apparently, Java 8 can use AES-NI (i.e. if the CPU supports AES-NI) and en/decryption should be much faster hence. I am looking forward to test if that improves performance of the decryption. [3,847 LOC]
2016-02-25: Rewriting the original file-based storage to a SQL database since files were not a feasible option any more. [3,621 LOC]
2016-02-24: Thinking about the scale the system will have to operate on. UK has 64 million people and about 33,000 cell towers. If cell tower ID was broadcasted together with the Anonymous ID, the brute force decryption would be reduced to about 64,000,000/33,000 which is about 2,000. According to my preliminary testing, this should take about 10 ms per Anonymous ID decryption. [3,101 LOC]
2016-02-23: More work on the server. The unique user ID generation works as well as the secret client-server key storage. [3,101 LOC]
2016-02-22: Initial work on the server: design, basic classes and protocols. Visualisation improved to skip inactive intervals of time (nights) and notify the user about it. [2,664 LOC]
2016-02-20: Logs processed into meeting logs. Visualisation of the logs and the meetings works, see the attached screenshot. The dots represent users moving around. As they move in time, their historical positions fade away. The circles represent exchange of Anonymous IDs, they also fade away as the time progresses. [2,409 LOC]
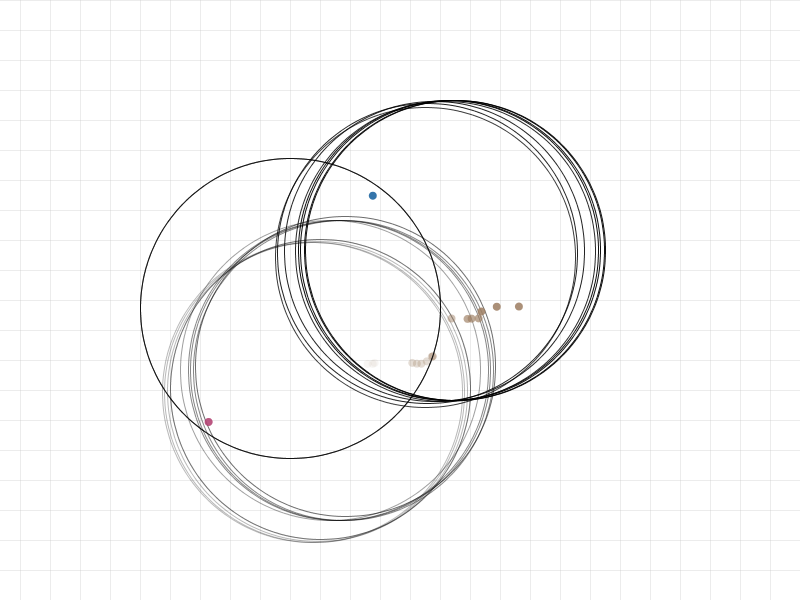
2016-02-19: Work on the logs and simulation which uses them. Logs are now cleaned (using proper filenames which order them by time) and separated into two categories: the old lab at origin (0, 0) and the new lab at origin (1000, 1000). I also cleaned the event times so that they are not relative to each file but absolute. Then I merged all the logs into a single file for ease of use.
Planned and thought through: The event logs will be processed into meeting logs: if two people were less than n meters away within m seconds a meeting event (A heard B and B heard A) will be generated. Initial guess for the values is n = 10 m, m = 3 seconds. [1,804 LOC]
2016-02-16: Broadcasting Anonymous ID works. The system keeps window of the last three (maybe change this to five?) activities. If majority of them are moving activities (i.e. not “still”, “tilting” or “unknown”) then it stops broadcasting. If majority of the activities become non-moving again, a new Anonymous ID is generated and the client starts broadcasting it again. Fixed bug which caused multiple broadcasters to start at once. Some refactoring. [1,804 LOC]
2016-02-06: I thought about the packet format and decided to keep more to the BLE specification (i.e. don’t push data into the service UID fields). This will provide couple of benefits, mainly being able to distinguish my own packets. Data will be therefore sent in two packets: The first packet will contain the Anonymous ID + user group hint. The second packet will provide metadata, i.e. GPS coordinates and location string. [1,631 LOC]
2016-02-05: Went over the Cambridge Bat System logs that will be used for simulation of the system: There are about 34 million records in the logs. After anonymising the data, it will provide decent performance evaluation of my server. [1,631 LOC]
2016-02-02: BLE broadcast and BLE listening works. Now I am able to send messages from one Bellrock client to another. The messages are now logged on the other device and displayed to the user. I did some refactoring so my design now much cleaner and elegant (I learned how to use Android Services). Lot of work on the GUI and one fixed GUI bug. [1,631 LOC]
2016-02-01: Thinking about using asymmetric cipher for the UID anonymisation. RSA not usable, since the output with reasonable key size is at least 1,024 bits = 128 bytes >> 29 bytes I have available. ECC with key size 160 bits (= 20 bytes) could be a solution, but not a future-proof one.
2016-01-29: Got USB-micro to USB-C adapter, so I can finally debug on Nexus 5X. Now I can test BLE broadcast. Implemented the BLE broadcast, I can send up to 29 bytes of data in one packet (27 as normal data, 2 in the service UUID). It is kind of hacky, but hey, this is a research project. [1,136 LOC]
2016-01-27: About two-fold improvement of the performance of the brute-force decryption.
2016-01-26: More performance tests. Got a SRCF server. Ordered USB-A to USB-C cable. Learn how to do background Android apps which will be needed for the server communication and BLE listening and broadcasting. [1,013 LOC]
2016-01-25: Security fix in the UID encryption. Decryption (both normal and “brute force”) implemented. The brute force decryption of an Anonymous ID using database of 1,000,000 UIDs took less than 8 seconds. [1,008 LOC]
2016-01-24: Activity detection (detect if the device’s user is walking, running, cycling, etc.) works. This will be used for nonce changing to prevent tracking when the user moves. [650 LOC]
2016-01-19: Classes for UID and Anonymous ID with some helper methods. Everything protected by Unit Tests. ID Encryption tested with 1,000,000 IDs, all generated were unique. [400 LOC]
2016-01-18: The ID encryption works. Given a unique 12 byte ID it generates a 20 byte anonymous ID by appending 8 (secure) random bytes and encrypting the whole thing using AES in CTR mode and the key (128 bit at the moment) that the clients shares with the server.
2016-01-16: First version of the GUI done. Discovered the Android Beacon Library, which will be useful. Found out that Nexus 5 and Nexus 7 don’t support BLE transmitting.
2016-01-14: Downloaded Android Studio, first demo app launched on Android and in the emulator.
2016-01-13: Work on the project officially starts.
Libraries
- Guava 19.0 (extra collections and other convenient stuff)
- OpenCellID (approximate location of the phone)
- Minuscule 2.0 (visualisation of the Bat Logs)
- HSQLDB 2.3.3 (database engine)
- jUnit 4.12 (unit testing)